人工智能服务
>
模型训练
点击菜单进入人工智能菜单,然后点击左侧训练,进入训练页面。 选择区域后,可以根据名称和状态进行训练的搜索。
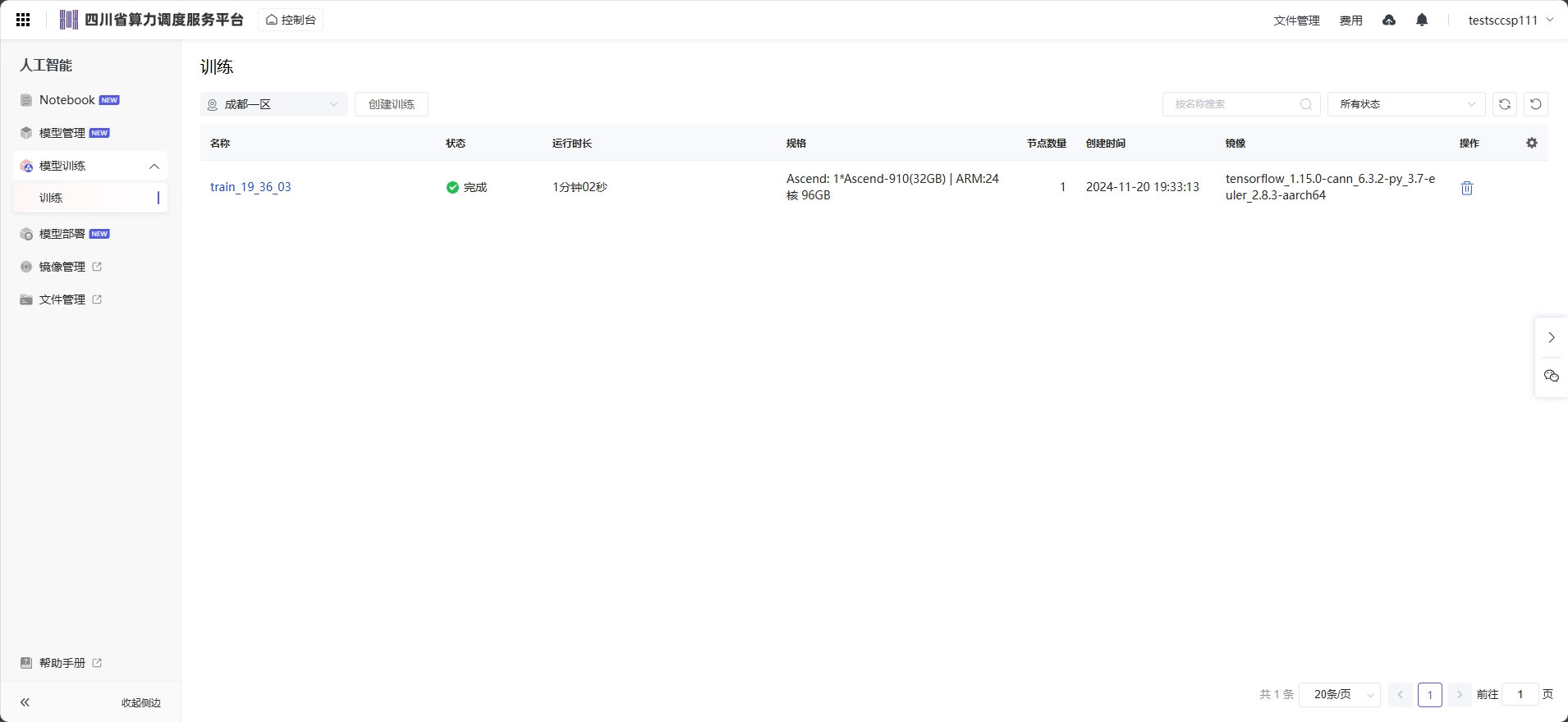
选择区域,然后点击创建训练弹出子页面,根据训练的代码选择规格、开发镜像可以选择预置镜像和我的镜像,填写对应的代码目录、启动文件、作业日志路径等信息,进行提交创建。
点击“创建训练”进入任务添加页面,各参数解释如下:
名称:表示该任务的名称且不允许重复;
加速卡类型:表示该任务的加速卡类型;
规格:表示该任务的训练使用的资源类型,根据不同的资源类型,选择所需的资源规格;
节点数量:表示工作节点的数量;
开发镜像:可以选择预制镜像和我的镜像;
代码目录:选择训练代码文件所在的目录;
启动文件:选择代码目录中训练作业的Python启动脚本。ModelArts只支持使用Python语言编写的启动文件,因此启动文件必须以“.py”结尾;
挂载路径:训练时容器内的路径,使用默认即可;
环境变量:训练时容器内的环境变量;(建议在代码中用环境变量的方式传递和获取路径,在代码中的可用路径是相对容器的路径,默认的工作目录为/home/ma-user/modelarts/user-job-dir 会将代码目录的文件夹 /userdata/home/用户名/code 挂载在工作目录下) 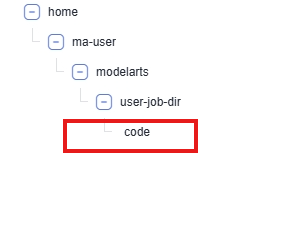 作业日志路径:训练产生的日志会持久化到对应的目录,用户可以进行日志查看分析;
作业日志路径:训练产生的日志会持久化到对应的目录,用户可以进行日志查看分析;
输入项:训练输入文件夹参数,可以选择路径;
输出项:训练输出文件夹参数,可以选择路径;
超时自动停止:运行时长到期后将会终止训练,准备排队等状态不扣除运行时长;
1、请确保代码中实现了定期保存模型的相关功能,以避免训练过程中出现异常导致训练模型丢失的情况。
2、因代码中未设置定期保存模型,导致训练作业被动终止时模型丢失,平台不承担任何责任。;
参数传递
import argparse
parser = argparse.ArgumentParser()
parser.add_argument('--data_path')
args, unknown = parser.parse_known_args()
data_path = args.data_path当参数的“获取方式”为“环境变量”时,可以参考如下代码来读取数据。
import os
data_path = os.getenv("data_path", "")
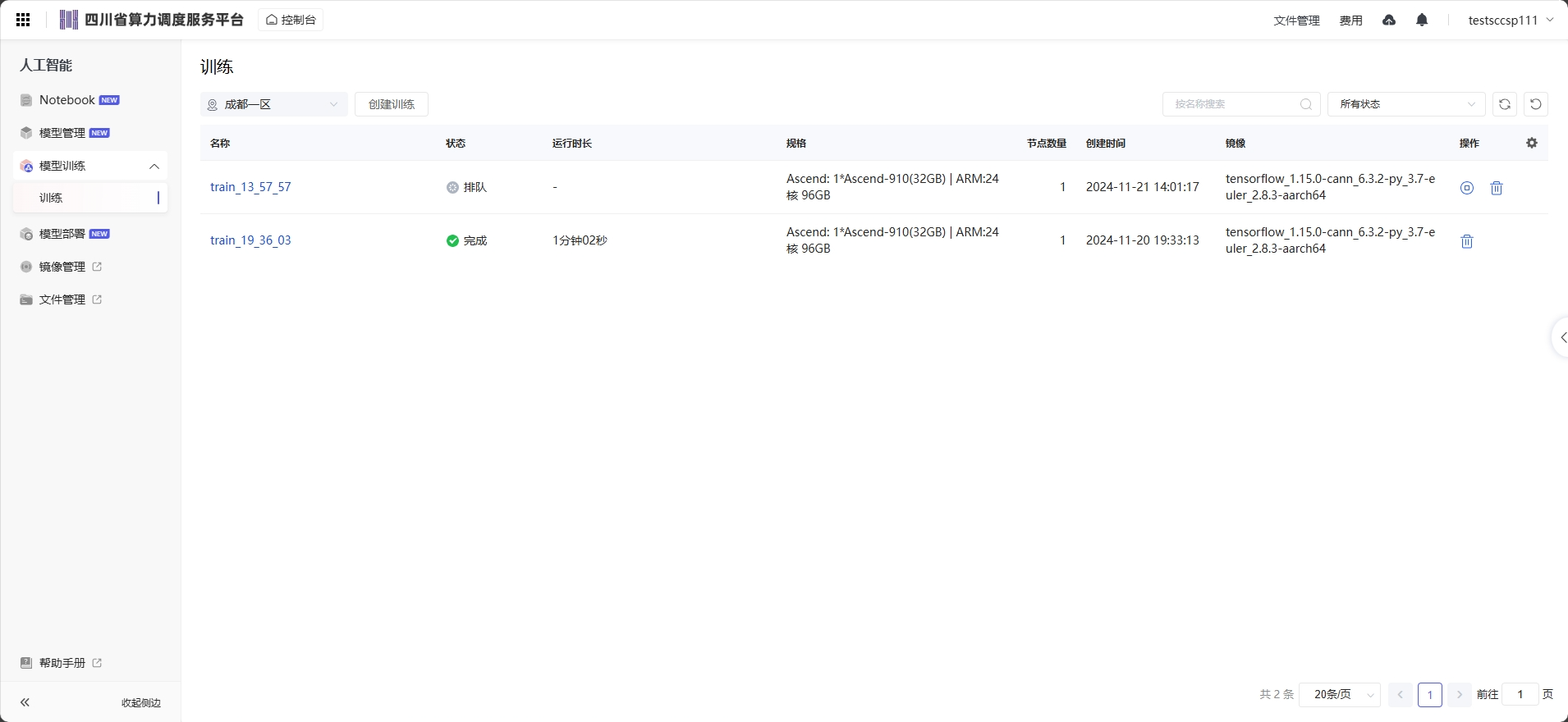
训练任务列表 页面显示已经创建过的模型训练任务,分为“名称”、“状态”、“运行时长”、“规格”、“节点数量”、“创建时间”和“镜像”列
停止训练作业 在训练作业列表中,针对“创建中”、“等待中”、“运行中”的训练作业,您可以单击“操作”列的“终止”,停止正在运行中的训练作业。 训练作业停止后,将停止计费。 运行结束的训练作业,如“已完成”、“运行失败”、“已终止”、“异常”的作业,不涉及“终止”操作。
删除训练作业 如果不再需要使用此训练任务,建议清除相关资源,避免产生不必要的费用。 在“训练作业”页面,删除运行结束的训练作业。您可以单击“操作”列的“删除”,在弹出的提示框中单击“确认”,删除对应的训练作业。
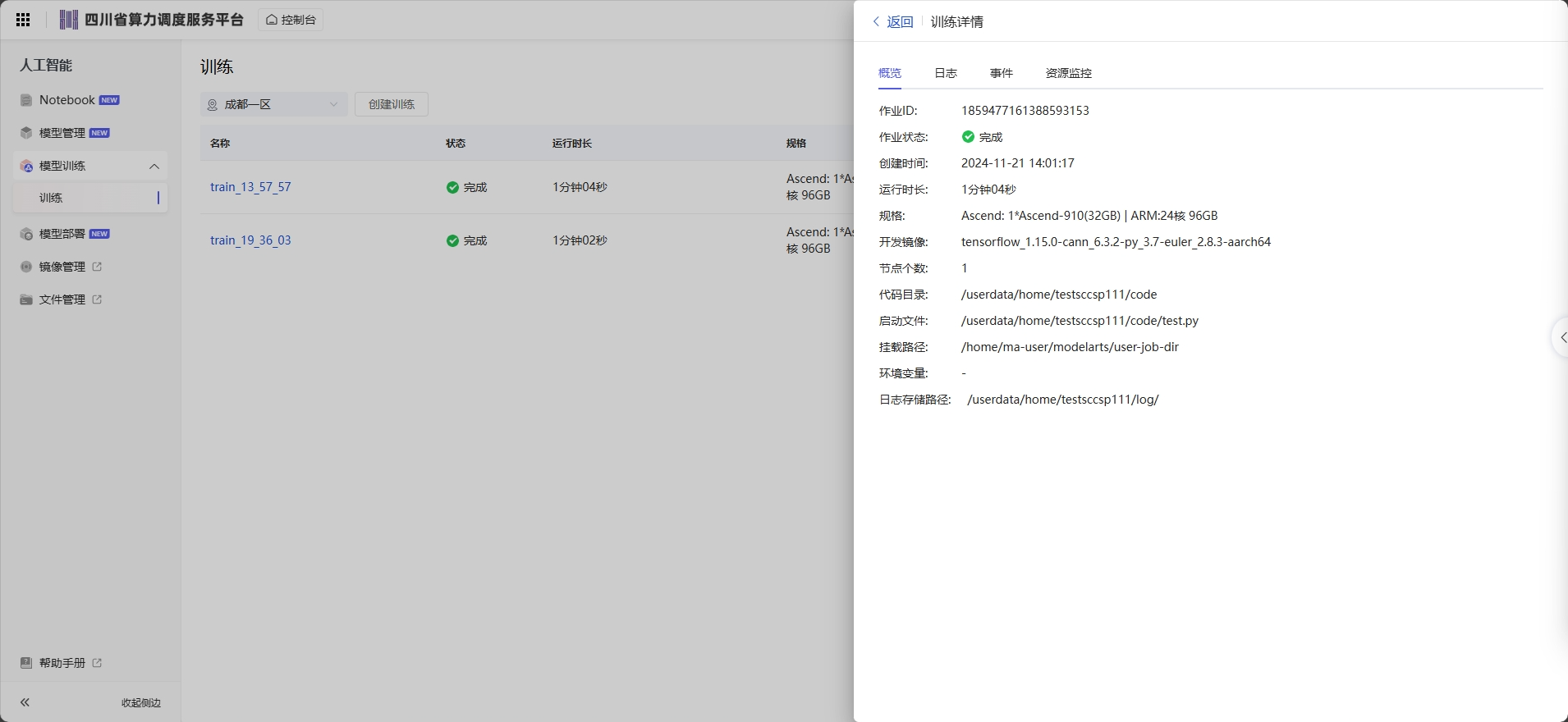
训练日志用于记录训练作业运行过程和异常信息,为快速定位作业运行中出现的问题提供详细信息。用户代码中的标准输出、标准错误信息会在训练日志中呈现。在训练作业遇到问题时,可首先查看日志,多数场景下的问题可以通过日志报错信息直接定位。
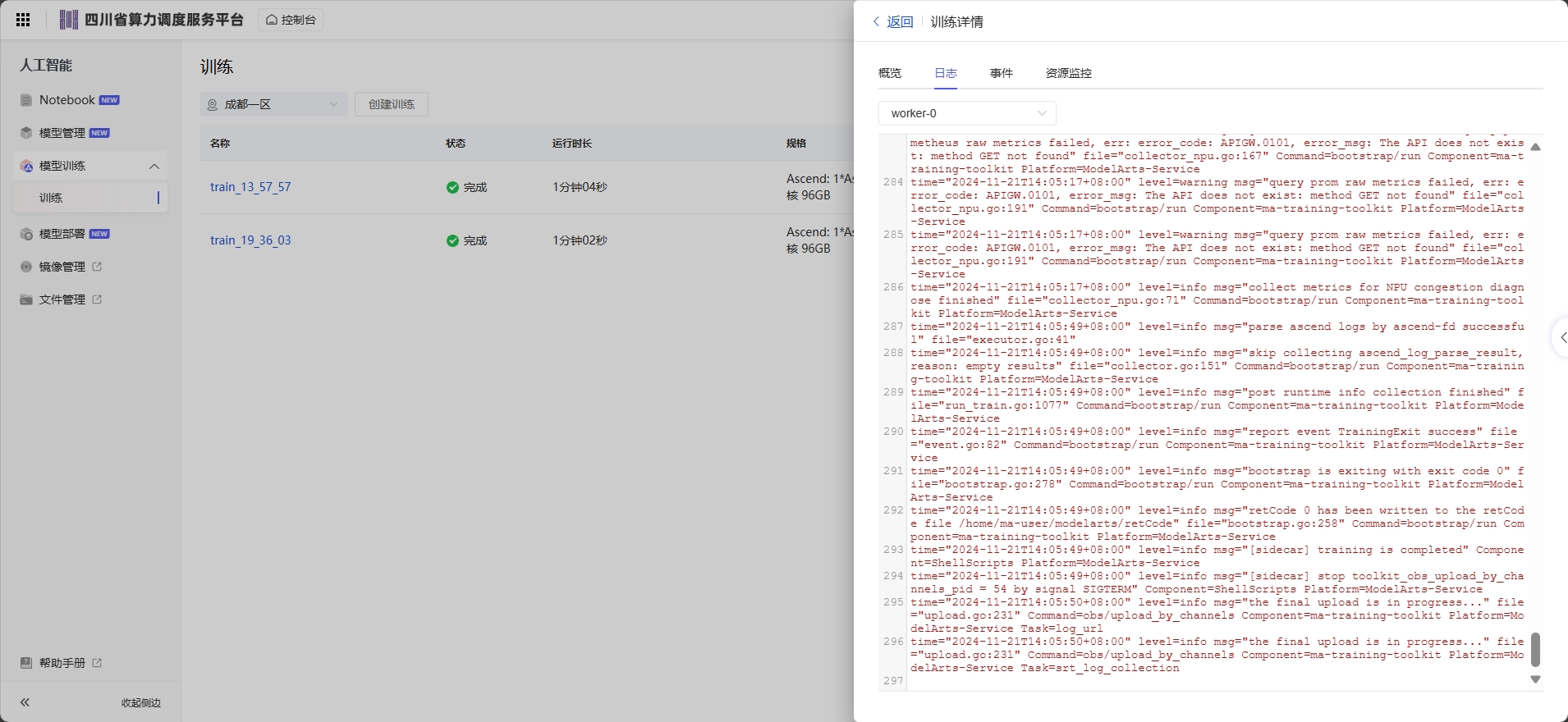
训练作业的(从用户可看见训练任务开始)整个生命周期中,每一个关键事件点在系统后台均有记录,用户可随时在对应训练作业的详情页面进行查看。
方便用户更清楚的了解训练作业运行过程,遇到任务异常时,更加准确的排查定位问题。
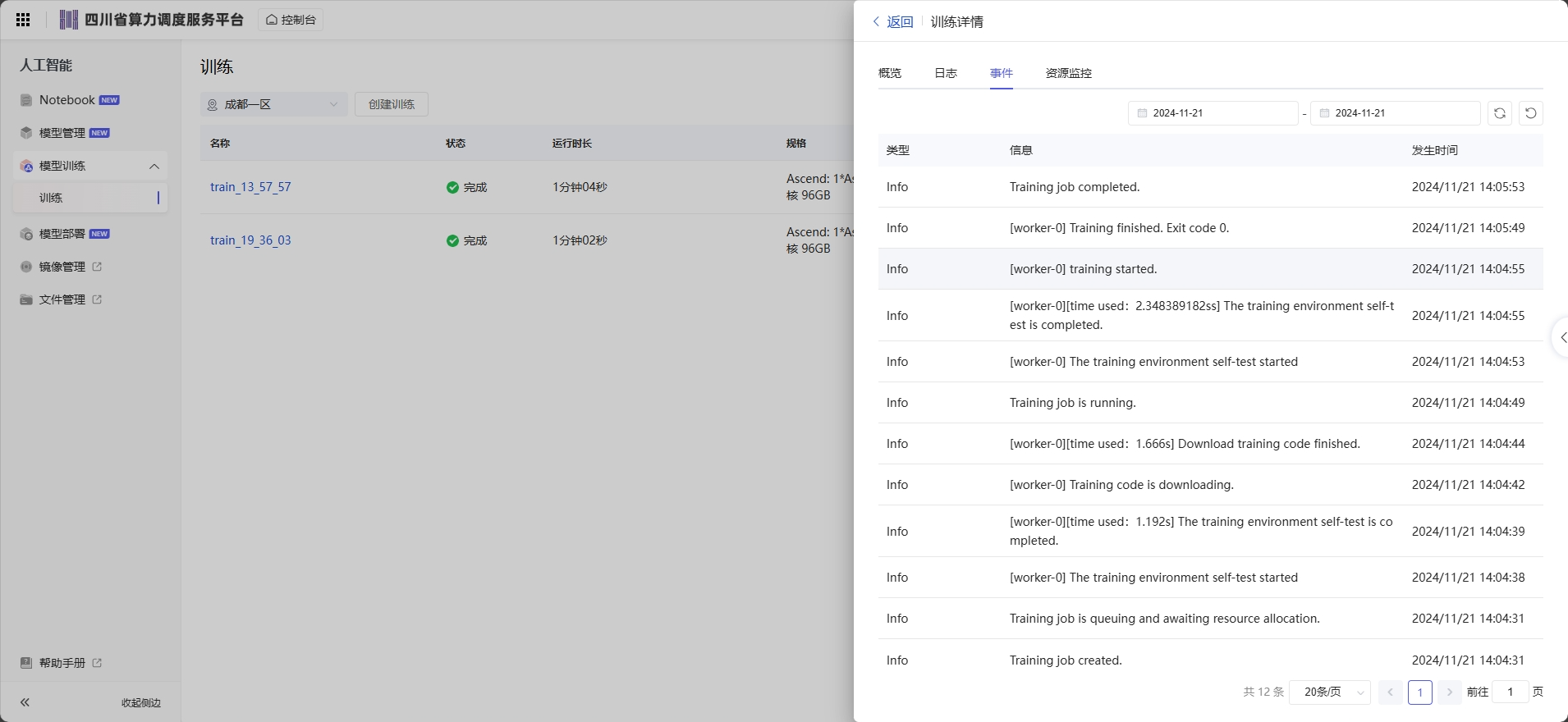
在训练作业详情页面,单击“资源占用情况”页签查看计算节点的资源使用情况,最多可显示最近三天的数据。在“资源占用情况”窗口打开时,会定期向后台获取最新的资源使用率数据并刷新。
操作一:如果训练作业使用多个计算节点,可以通过实例名称的下拉框切换节点。
操作二:单击图例 “cpuUsage”、“gpuMemUsage”、“gpuUtil”、“memUsage”“npuMemUsage”、“npuUtil”,可以添加或取消对应参数的使用情况图。
操作三:鼠标悬浮在图片上的时间节点,可查看对应时间节点的占用率情况。
如何提高训练作业资源利用率 适当增大batch_size:较大的batch_size可以让GPU/NPU计算单元获得更高的利用率,但是也要根据实际情况来选择batch_size,防止batch_YLLsize过大导致内存溢出。 提升数据读取的效率:如果读取一个batch数据的时间要长于GPU/NPU计算一个batch的时间,就有可能出现GPU/NPU利用率上下浮动的情况。建议优化数据读取和数据增强的性能,例如将数据读取并行化,或者使用NVIDIA Data Loading Library(DALI)等工具提高数据增强的速度。 模型保存不要太频繁:模型保存操作一般会阻塞训练,如果模型较大,并且较频繁地进行保存,就会影响GPU/NPU利用率。同理,其他非GPU/NPU操作尽量不要阻塞训练主进程太多的时间,如日志打印,保存训练指标信息等。