人工智能服务
>
实践案例
>
Qwen1.5-7B 910A 微调/推理
进入控制台,在控制台首页,选择“人工智能”进入创建Notebook界面,选择mindspore 2.2镜像 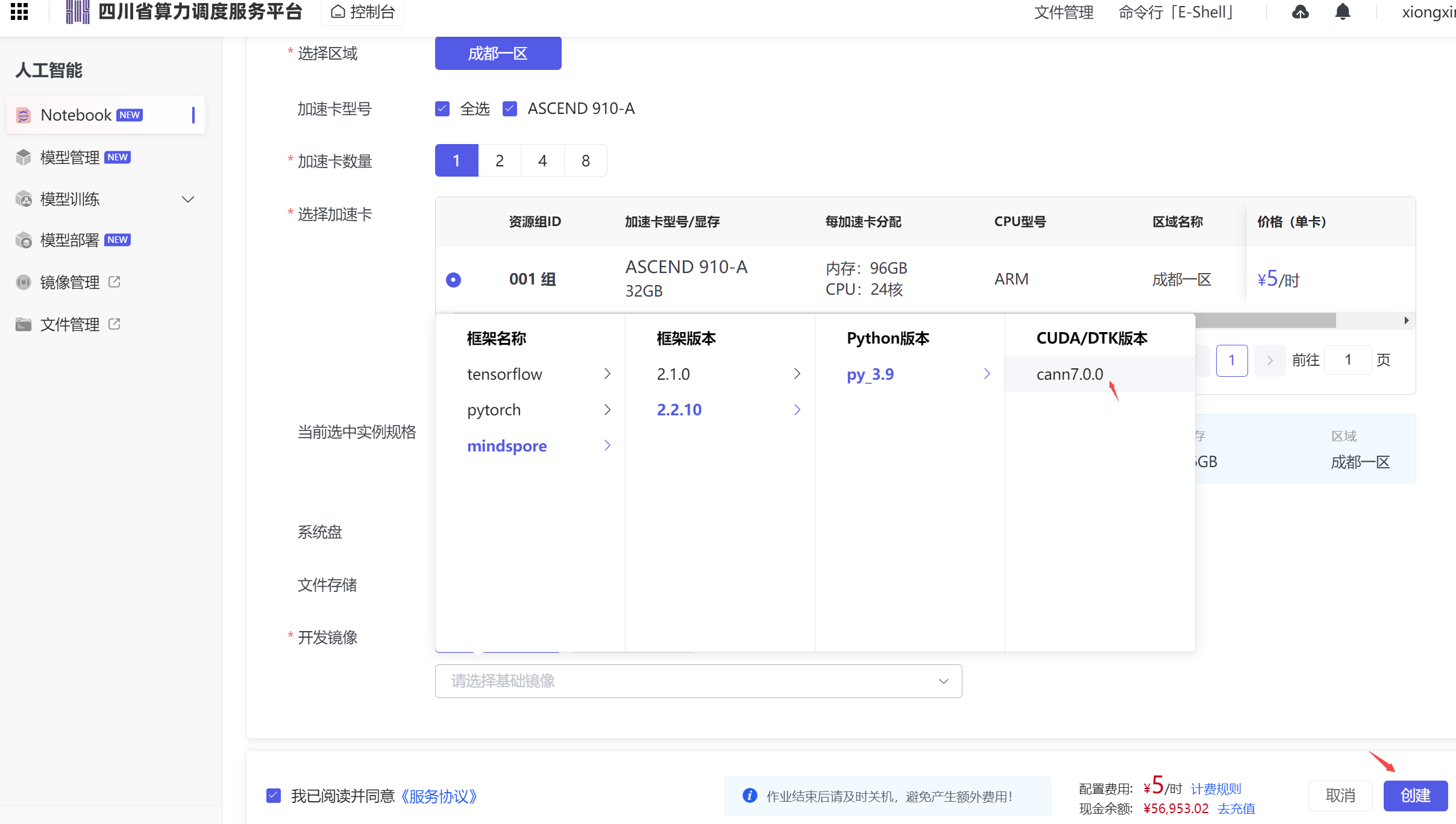
待notebook创建成功后,点击"访问服务"进入jupterlab页面,点击进入控制台 
pip install -U mindspore==2.2.14进入环境拉取 mindformers 仓库:cd /home/ma-user/work && git clone https://gitee.com/mindspore/mindformers.git
切换分支:cd mindforme && git checkout origin/r1.0.a
安装依赖:pip install -r requirements.txt
配置环境变量: export PYTHONPATH=/home/ma-user/work/mindformers:$PYTHONPATH#下载 acctransformer仓库
git clone -b fa1_for_ms2.2.11 https://gitee.com/mindspore/acctransformer.git
#设置 PYTHONPATH
export PYTHONPATH=/yourcodepath/acctransformer/train:$PYTHONPATH ##注意修改yourcodepath
#安装 whl
cd train
python setup.py install可以直接使用 /user/config/jobstart_hccl.json
ps. 请将整个文件目录全部下载 安装模型转换依赖
pip install torch transformers transformers_stream_generator einops accelerate使用alpaca 数据集 数据集下载链接如下:
执行python alpaca_converter.py将原始数据集转换为指定格式
python qwen1_5/alpaca_converter.py \
--data_path path/alpaca_data.json \
--output_path /path/alpaca-data-messages.json
# 参数说明
# data_path: 存放alpaca数据的路径
# output_path: 输出转换后对话格式的数据路径转换后格式样例:
{
"type": "chatml",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Give three tips for staying healthy."
},
{
"role": "assistant",
"content": "1.Eat a balanced diet and make sure to include plenty of fruits and vegetables. \n2. Exercise regularly to keep your body active and strong. \n3. Get enough sleep and maintain a consistent sleep schedule."
}
],
"source": "unknown"
},执行python qwen1_5_preprocess.py进行数据预处理和 Mindrecord 数据生成。 注意路径的修改
python qwen1_5/qwen1_5_preprocess.py \
--input_glob /path/alpaca-data-messages.json \
--vocab_file /path/vocab.json \
--merges_file /path/merges.txt \
--seq_length 2048 \ #此样例lora用的2k数据,finetune用的4k数据,生成不同长度数据集修改此处
--output_file /path/alpaca-messages.mindrecord1 参照数据集准备章节获取 mindrecord 格式的 alpaca 数据集,参照模型权重准备章节获取权重。
2 当前支持模型已提供 yaml 文件,下文以 Qwen-7B 为例,即使用run_qwen1_5_7b_lora.yaml配置文件进行介绍,请根据实际使用模型更改配置文件。
修改run_qwen1_5_7b_lora.yaml中下面的配置,默认开启自动权重转换,使用完整权重
load_checkpoint: '/path/model_dir' # 使用完整权重,权重按照`model_dir/rank_0/xxx.ckpt`格式存放
auto_trans_ckpt: True # 打开自动权重转换
use_parallel: True
run_mode: 'finetune'
model:
seq_length: 2048 # 与数据集长度保持相同
use_flash_attention: True # 开启fa
train_dataset: &train_dataset
data_loader:
type: MindDataset
dataset_dir: "/path/alpaca.mindrecord" # 配置训练数据集文件夹路径,写到alpaca.mindrecord,目录下确认要有alpaca.mindrecord和alpaca.mindrecord.bd
# 8卡分布式策略配置
parallel_config:
data_parallel: 4
model_parallel: 2
pipeline_stage: 1
micro_batch_num: 1
vocab_emb_dp: True
gradient_aggregation_group: 4
context:
max_device_memory: "31GB"3 启动 lora 微调 启动运行脚本, 进行单节点 8 卡分布式运行
cd mindformers/research
#注意路径的替换
bash run_singlenode.sh "python qwen1_5/run_qwen1_5.py \
--config qwen1_5/run_qwen1_5_7b_lora.yaml \
--load_checkpoint model_dir \
--use_parallel True \
--run_mode finetune \
--auto_trans_ckpt True \
--train_data dataset_dir" \
/user/config/jobstart_hccl.json [0,8] 8
# 参数说明
# config: 配置文件路径
# load_checkpoint: 权重文件夹路径
# auto_trans_ckpt: 自动权重转换开关
# use_parallel: 开启并行模式
# run_mode: 运行模式,微调时设置为finetune
# train_data: 训练数据集文件夹路径运行过程示例: 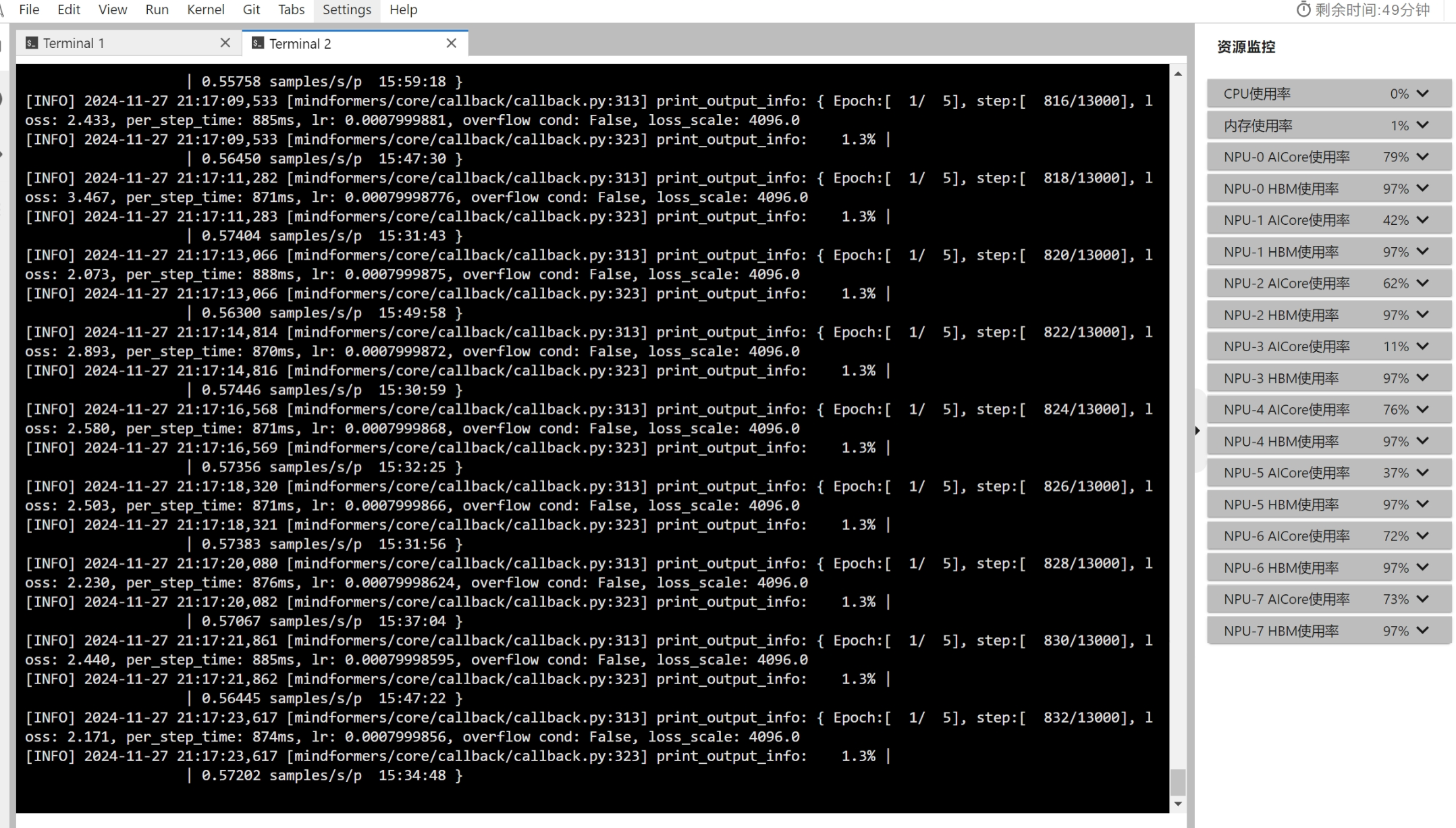
当前支持模型已提供 yaml 文件,下文以 qwen1_5 为例,即使用 run_qwen1_5_7b_infer.yaml 配置文件进行介绍,请根据实际使用模型更改配置文件。
使用单卡推理
1.修改配置
load_checkpoint: '/path/model_dir' # 使用完整权重,权重存放格式为"model_dir/rank_0/xxx.ckpt"
auto_trans_ckpt: False # 关闭自动权重转换
use_past: True # 使用增量推理
use_parallel: True # 使用并行模式
processor:
tokenizer:
vocab_file: "/{path}/vocab.json" # vocab.json文件路径
merges_file: "/{path}/merges.txt" # merges.txt文件路径
parallel_config:
data_parallel: 1
model_parallel: 1
pipeline_stage: 1
micro_batch_num: 1
vocab_emb_dp: True2.启动推理
cd mindformers/research
# 推理命令中参数会覆盖yaml文件中的相同参数
python qwen1_5/run_qwen1_5.py \
--config qwen1_5/run_qwen1_5_7b_infer.yaml \
--run_mode predict \
--use_parallel True \
--load_checkpoint /path/model_dir \
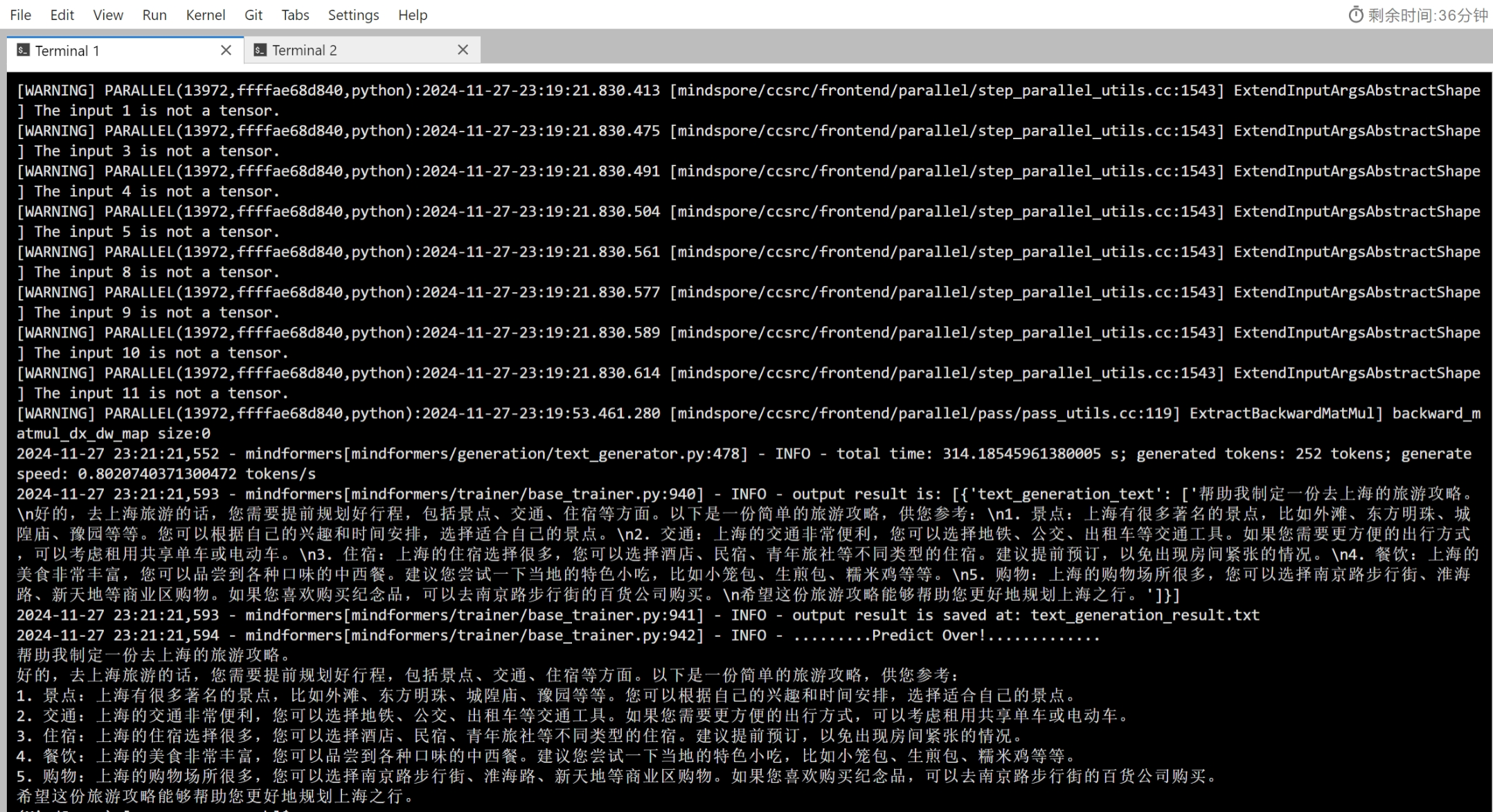
--predict_data 帮助我制定一份去上海的旅游攻略
#推理完成 响应如下
# 帮助我制定一份去上海的旅游攻略。
#好的,去上海旅游的话,您需要提前规划好行程,包括景点、交通、住宿等方面。以下是一份简单的旅游攻略,供您参考:
# 1. 景点:上海有很多著名的景点,比如外滩、东方明珠、城隍庙、豫园等等。您可以根据自己的兴趣和时间安排,选择适合自己的景点。
# 2. 交通:上海的交通非常便利,您可以选择地铁、公交、出租车等交通工具。如果您需要更方便的出行方式,可以考虑租用共享单车或电动车。
# 3. 住宿:上海的住宿选择很多,您可以选择酒店、民宿、青年旅社等不同类型的住宿。建议提前预订,以免出现房间紧张的情况。
# 4. 餐饮:上海的美食非常丰富,您可以品尝到各种口味的中西餐。建议您尝试一下当地的特色小吃,比如小笼包、生煎包、糯米鸡等等。
# 5. 购物:上海的购物场所很多,您可以选择南京路步行街、淮海路、新天地等商业区购物。如果您喜欢购买纪念品,可以去南京路步行街的百货公司购买。
# 希望这份旅游攻略能够帮助您更好地规划上海之行。运行结果示例: